Безопасность компании стоит дорого: вы покупаете лицензии на тяжеловесные системы, нанимаете команду экспертов и тратите сотни часов на настройку правил. Но как понять, что эти инвестиции не улетают в трубу? Если руководитель спрашивает: «Насколько мы защищены?», ответ «Вроде бы всё спокойно» не подходит. Вам нужны цифры, которые отражают реальную работу Security Operations Center (SOC) и эффективность SIEM-системы.
Эффективность информационной безопасности — это не отсутствие взломов (хакеры могут просто ждать подходящего момента), а скорость и точность вашей реакции на угрозы.
Почему «пустые» метрики вредят работе
Многие команды совершают ошибку, измеряя активность, а не результат. Например, количество собранных логов в сутки само по себе ничего не говорит о безопасности. Вы можете хранить терабайты мусорных данных, которые не помогают ловить злоумышленников, а только забивают дисковое пространство и бюджет.
Другой пример бесполезного показателя — общее количество сработавших правил корреляции. Если SIEM заваливает аналитиков сотнями алертов, из которых 99% — ложные срабатывания (False Positives), такая система работает против вас. Команда просто выгорает, перестает доверять уведомлениям и в итоге пропускает реальную атаку. Правильные метрики должны показывать качество обнаружения и скорость нейтрализации опасности.
Важно помнить! Эффективный SOC не тот, где экран «горит красным» от сотен уведомлений, а тот, где каждое уведомление имеет смысл и четкий алгоритм отработки.
Главные временные показатели: MTTD и MTTR
В индустрии информационной безопасности есть два «золотых» параметра, по которым оценивают зрелость мониторинга. Это скорость обнаружения и скорость реагирования. Именно они показывают, насколько быстро вы сокращаете «время присутствия» хакера в вашей сети.
- MTTD (Mean Time to Detect) — среднее время обнаружения. Это период с момента начала атаки до того момента, как SIEM сгенерировала алерт, а аналитик его заметил. Чем меньше этот срок, тем меньше данных успеет украсть злоумышленник. В идеале счет должен идти на минуты.
- MTTR (Mean Time to Respond) — среднее время реагирования. Показывает, сколько времени уходит у команды на локализацию угрозы после её обнаружения. Сюда входит анализ инцидента, блокировка учетных записей или отключение зараженного узла от сети.
- Время подтверждения инцидента. Интервал между алертом в системе и моментом, когда человек нажал кнопку «В работе». Если этот показатель растет, значит, аналитики перегружены.
- Длительность расследования. Время, которое тратит эксперт, чтобы восстановить цепочку событий. Если расследование затягивается, возможно, в SIEM не хватает контекстных данных или инструменты поиска слишком неудобные.
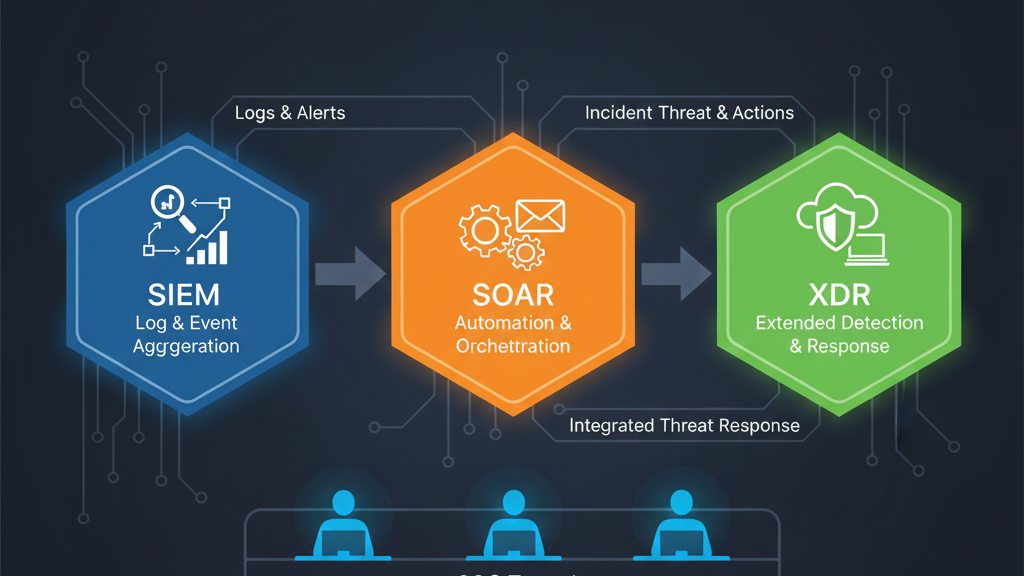
Оценка качества работы SIEM-системы
SIEM — это «мозг» вашего SOC. Чтобы он работал эффективно, его нужно постоянно «тренировать» и проверять на адекватность. Здесь мы смотрим не на время, а на точность работы алгоритмов.
Для оценки полезности системы стоит отслеживать долю ложных срабатываний (False Positive Rate). Если вы постоянно донастраиваете исключения, а поток «шума» не падает, значит, правила корреляции написаны слишком обобщенно.
Также важно следить за полнотой данных. Для этого используют следующие показатели:
- Покрытие инфраструктуры источниками. Какое количество критичных серверов, баз данных и сетевых устройств реально отдают логи в SIEM. Дыры в мониторинге — это слепые зоны для защиты.
- EPS (Events Per Second) и его динамика. Среднее количество событий в секунду. Резкие скачки могут сигнализировать либо об атаке (например, брутфорс паролей), либо о техническом сбое на источнике.
- Качество парсинга (разбора) данных. Какой процент логов система понимает и раскладывает по полям. Если логи приходят в виде «сырой» строки, вы не сможете построить по ним качественную корреляцию.
- Актуальность правил детектирования. Процент правил, которые реально срабатывали за последние 3–6 месяцев. Забытые и неактуальные правила только замедляют работу поискового движка.
Человеческий фактор и производительность команды
Даже самая дорогая SIEM бесполезна без грамотных людей. Метрики SOC должны учитывать нагрузку на сотрудников, чтобы предотвратить текучку кадров.
Один из ключевых показателей здесь — количество инцидентов на одного аналитика. Если на человека падает по 50 событий в смену, он физически не сможет провести глубокий анализ. В такой ситуации страдает качество, а риск ошибки растет.
Также стоит измерять уровень автоматизации. Посчитайте, какую долю рутинных операций (например, проверку IP-адреса по базам фишинга) выполняют скрипты или SOAR-системы. Чем выше этот процент, тем больше времени у экспертов остается на поиск сложных угроз (Threat Hunting).
Мнение эксперта: Если ваш аналитик тратит 80% времени на копирование хешей из одного окна в другое, вы переплачиваете за ручной труд. Автоматизируйте сбор контекста, чтобы люди занимались принятием решений, а не рутиной.

Как бизнес видит эффективность безопасности
Для топ-менеджмента технические детали вроде EPS или задержки парсинга не имеют значения. Бизнесу нужно понимать риски и деньги. Чтобы говорить с руководством на одном языке, переводите метрики в плоскость влияния на компанию.
Эффективность SOC для бизнеса можно выразить через предотвращенный ущерб. Попробуйте оценить потенциальную стоимость простоя критичного сервиса и сравните её с временем, за которое SOC устранил инцидент. Если система обнаружила шифровальщик на этапе первичного проникновения, вы сэкономили компании миллионы.
Также важно отслеживать динамику стоимости обработки одного инцидента. При правильной настройке процессов и внедрении автоматизации эта цифра должна постепенно снижаться, несмотря на рост объема данных.
Финальный чек-лист для проверки мониторинга
Чтобы оценка не превратилась в отчет ради отчета, выберите 5–7 показателей, которые вы будете отслеживать ежемесячно. Помните, что цифры без контекста бесполезны — всегда ищите причину изменений.
- Сравните MTTD текущего месяца с предыдущим: если время растет, ищите проблемы в правилах SIEM.
- Проверьте топ-10 самых «шумных» правил: каждое из них должно быть либо оптимизировано, либо отключено.
- Оцените долю автоматизированных ответов на типовые инциденты.
- Проведите инвентаризацию источников: все ли критичные системы под присмотром?
- Опросите аналитиков на предмет удобства интерфейса и скорости поиска в базе событий.
Регулярный замер метрик превращает кибербезопасность из «черного ящика» в управляемый и прозрачный процесс. Когда вы видите слабые места в цифрах, вы точно знаете, куда направить бюджет и усилия команды в следующем квартале.